
Recently, we upgraded Tableau from version 8.0 (32 Bits) to 8.1.7 (64 Bits) along with Automatic Login (Single Sign On) and PostgreSQL configuration (Access to the Tableau system Database). After the successful upgrade of this application and configuration of the named features, I would like to share my experience as they may be useful in case you face a similar situation.
Clariba receives certification for SAP recognized expertise in business intelligence and SAP HANA
Business Intelligence for SMEs - faster time to value and more affordable than ever
Given the fierce competition and the ever-soaring demands of customers, small and medium-sized enterprises (SMEs) today need to invest in having BI capabilities to stay relevant and meet these demands. Yet, with scarce resources available, the alignment of business and IT is vital to ensure success, and new options for hosted BI solutions freeing up cash flow are attractive options for SMEs.
Top Wins of SAP Business Warehouse (BW) and Why Clariba can Implement this BW Solution
What top BI and analytics trends and predictions in 2014 to watch out for?
Is your organization ready for “After Big Data”?
A recent article in the Harvard Business Review by Thomas Davenport, professor and fellow at MIT, caught my attention. Davenport refers to the beginnings of a new era: “After Big Data” in his article Analytics 3.0. While organizations built around massive data volumes — such as Facebook, LinkedIn, eBay, Amazon and others — may be ready to move to the next wave of analytics, the full spectrum of big data capabilities is yet to be realized in the traditional organizations we work with on a daily basis.
Do you know what drives your business?
Knowing your business and making smarter decision in order to keep up with the everyday risks involved in running your business is critical in order to survive in today’s global economy.
 Making effective decisions requires information. This information must be accurate and updated, and in the right level of detail that you need to be able to move forward at optimal speed. Key business analytics is what allows you to draw information from the data you collect in the different parts of your business. When you understand exactly what is driving your business, where new opportunities come from, and where mistakes were made, you can be proactive to maximize existing revenues and reveal areas for expansion. Better decisions can be made when you have more visibility into vital insight coming from your own company.
Making effective decisions requires information. This information must be accurate and updated, and in the right level of detail that you need to be able to move forward at optimal speed. Key business analytics is what allows you to draw information from the data you collect in the different parts of your business. When you understand exactly what is driving your business, where new opportunities come from, and where mistakes were made, you can be proactive to maximize existing revenues and reveal areas for expansion. Better decisions can be made when you have more visibility into vital insight coming from your own company.
SAP Business Intelligence (BI) Solutions provides a window into your company. A dashboard for example is a single, reliable, and real-time overview of your company. It offers you quick insight, in visual appealing formats that are easy to understand. You also have "What-If" tests that let you measure the business impact of a particular change. This can also be made available on mobile devices, so you can make informed decisions on-the-move. When you have information you can trust, you are able to act rapidly and stay ahead of the game.
With years of expertise in BI, Clariba has helped several companies to draw insight from their data. For example, Vodafone Turkey´s Marketing department sought our help to provide the Customer Value Management Team with a dynamic and user-friendly visualization and analysis tool for marketing campaigns. With the central dashboard we delivered, the marketing team was able to analyze existing campaigns and design outlines for new ones based on key success factors.
You can learn more about SAP BI solutions here, and you can also watch SAP BI Solutions videos on YouTube. Want to unlock this information on what drives your business forward? Contact us on info@clariba or leave a comment below, and discover how SAP BI Solutions can help you achieve it.
BI and Social Media – A Powerful Combination (Part 2: Facebook)
To continue with my Social Media series (read the previous blog here BI and Social Media – A Powerful Combination Part 1: Google Analytics), today I would like to talk about the biggest social network of them all: Facebook. In this blog post, I will explain different alternatives I have recently researched to extract and use information from Facebook to perform social media analytics with SAP BusinessObjects’ report and dashboard tools. In terms of the amount of useful information we can extract to perform analytics, I personally think that Twitter can be as good or even better than Facebook, however, it has around 400 million less users. Facebook still stands as the social network with the most users around the world - 901million at this moment - making it a mandatory reference in terms of social media analytics.
Before we start talking about technical details, the first thing you should understand is that Facebook is strongly focused on user experience, entertainment applications, content sharing, among others. Therefore, the user activity is more dispersed and variable as opposed to the real-time orderly fashion that Twitter gives us, which is so useful when building trends and chronological analysis. Hence, be sure of what you are looking for, stay focused on your key indicators and make sure you are searching for something that is significant and measurable.
Relevant Facebook APIs for Analytical purposes
The APIs (Application Programming Interface) that Facebook provides are largely directed at the development of applications for social networking and user entertainment. However, there are several APIs that can provide relevant information to establish Key Indicators that can later be used to run reports. As Facebook’s developer page1 states: “ We feel the best API solutions will be holistic cross API solutions.” Among the API’s that you will find most useful (labeled by Facebook as Marketing APIs), I can highlight the Graph API, the Pages API, the Ads API and the Insights API. In any case, I encourage you to take a look at Facebook pages and guides for developers, it will be worth your time:
Marketing Developer Program
Marketing Developer Resources (with mentions of the APIs above)
Facebook Marketing Solutions: http://www.facebook.com/marketing

Facebook APIs
Third party applications to extract data from Facebook
I only found a few third party applications to extract data from Facebook’s API that were comprehensive enough to ensure reliable access to data. Below are some alternatives designed for this requirement:
GA Data Grabber: This application has a module for the Facebook APIs, which costs 500USD a year. As in the case of Google Analytics, it has key benefits such as ease-of-use and flexibility to make queries. It may also be integrated with some tools from SAP BusinessObjects such as WebIntelligence, Data Integrator or Xcelsius dashboards through LiveOffice.2
Custom Application Development: It is the most popular option, as I already mentioned in my previous post about Google Analytics. The Facebook APIs admit access from common programming languages, allowing to record the results of the queries in text files that can be loaded into a database or incorporated directly into various tools of SAP BusinessObjects.
Implementation of a Web Spider: If the information requirements are more focused on the user’s interactions with your client’s Facebook webpage or any of its related Facebook applications, this method may provide complementary information to that which is available in the APIs. The information obtained by the web spider can be stored in files or database for further integration with SAP BusinessObjects tools. Typically, web spiders are developed in a common programming language, although there are some cases where you can buy an application developed by third parties, as the case of Mozenda.3
Final Thought
As I have mentioned in my previous post, in the area of Social Media new applications and trends are appearing at a hectic pace, a lot of changes are expected to happen, so it is just a matter of time until we have more and better options available. I encourage you to stay curious on Social Media analytics and its most popular networks, because right now this is a growing gold mine of information.

If you have any questions or anything to add to help improve this post, please feel free to leave your comments.
B-tree vs Bitmap indexes: Consequences of Indexing - Indexing Strategy for your Oracle Data Warehouse Part 2
On my previous blog post B-tree vs Bitmap indexes - Indexing Strategy for your Oracle Data Warehouse I answered two questions related to Indexing: Which kind of indexes can we use and on which tables/fields we should use them. As I promised at the end of my blog, now it´s time to answer the third question: what are the consequences of indexing in terms of time (query time, index build time) and storage?
Consequences in terms of time and storage
To tackle this topic I’ll use a test database with a very simplified star schema: 1 fact table for the General Ledger accounts balances and 4 dimensions - the date, the account, the currency and the branch (like in a bank).
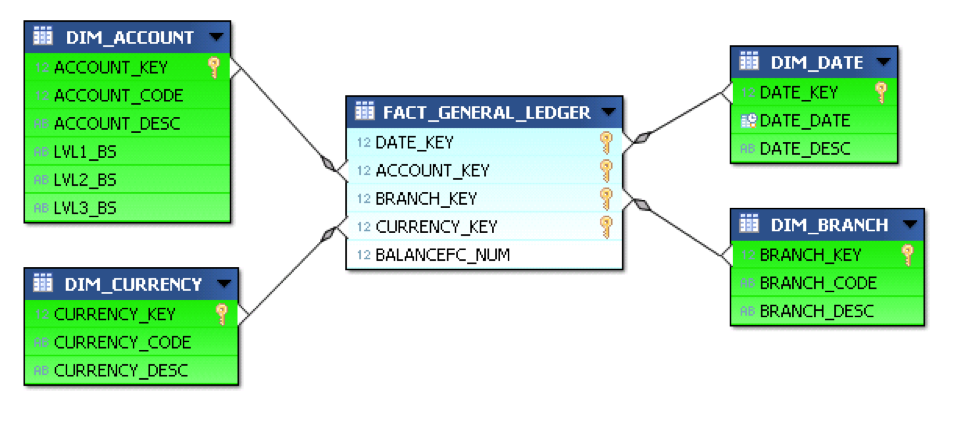
Simplified Star Schema
To give an idea of the table size, Fact_General_Ledger has 4,5 million rows, Dim_Date 14 000, Dim_Account 3 000, Dim_Branch and Dim_Currency less than 200.
We’ll suppose here that the users could query the data with filter on the date, branch code, currency code, account code, and the 3 levels of the Balance Sheet hierarchy (DIM_ACCOUNT.LVLx_BS) . We assume that the descriptions are not used in filters, but in results only.
Here is the query we will use as a reference:
Select
d.date_date,
a.account_code,
b.branch_code,
c.currency_code,
f.balance_num
from fact_general_ledger f
join dim_account a on f.account_key = a.account_key
join dim_date d on f.date_key = d.date_key
join dim_branch b on f.branch_key = b.branch_key
join dim_currency c on f.currency_key = c.currency_key
where
a.lvl3_bs = 'Deposits With Banks' and
d.date_date = to_date('16/01/2012', 'DD/MM/YYYY') and
b.branch_code = 1 and
c.currency_code = 'QAR' -- I live in Qatar ;-)
So, what are the results in terms of time and storage?

Time and Storage Comparison
Some of the conclusions we can draw from this table are:
Using indexes pays off: queries are really faster (about 100 times), whatever the chosen index type is.
Concerning the query time, the index type doesn’t seem to really matter for tables which are not that big. It would probably change for a fact table with 10 billion rows. There seems however to be an advantage to bitmap indexes and especially bitmap join indexes (have a look at the explanation plan cost column).
Storage is clearly in favor of bitmap and bitmap join indexes
Index build time is clearly in favor of b-tree. I’ve not tested the index update time, but the theory says it’s much quicker for b-tree indexes as well.
Ok, I´m convinced to use Indexes. How do I create/maintain one?
The syntax for creating b-tree and bitmap indexes is similar:
Create Bitmap Index Index_Name ON Table_Name(FieldName)
In the case of b-tree indexes, simply remove the word “Bitmap” from the query above.
The syntax for bitmap join indexes is longer but still easy to understand:
create bitmap index ACCOUNT_CODE_BJ
on fact_general_ledger(dim_account.account_code)
from fact_general_ledger,dim_account
where fact_general_ledger.account_key = dim_account.account_key
Note that during your ETL, you’d better drop/disable your bitmap / bitmap join indexes, and re-create/rebuild them afterwards, rather than update them. It is supposed to be quicker (however I’ve not made any tests).
The difference between drop/re-create and disable/rebuild is that when you disable an index, the definition is kept. So you need a single line to rebuild it rather than many lines for the full creation. However the index build times will be similar.
To drop an index: “drop index INDEX_NAME”
To disable an index: “alter index INDEX_NAME unusable”
To rebuild an index: “alter index INDEX_NAME rebuild”
Conclusion
The conclusion is clear: USE INDEXES! When properly used, they can really boost query response times. Think about using them in your ETL as well: making lookups can be much faster with indexes.
If you’d like to go any further I can only recommend that you read the Oracle Data Warehousing Guide. To get it just look for it on the internet (and don’t forget to specify the version of your database – 10.2, 11.1, 11.2, etc.). It’s a quite interesting and complete document.
B-tree vs Bitmap indexes - Indexing Strategy for your Oracle Data Warehouse Part 1
Some time ago we’ve seen how to create and maintain Oracle materialized views in order to improve query performance. But while materialized views are a valuable part of our toolbox, they definitely shouldn’t be our first attempt at improving a query performance. In this post we’re going to talk about something you’ve already heard about and used, but we will take it to the next level: indexes.
Why should you use indexes? Because without them you have to perform a full read on each table. Just think about a phone book: it is indexed by name, so if I ask you to find all the phone numbers of people whose name is Larrouturou, you can do that in less than a minute. However if I ask you to find all the people who have a phone number starting with 66903, you won’t have any choice but reading the whole phone book. I hope you don’t have anything else planned for the next two months or so.

Searching without indexing
It’s the same thing with database tables: if you look for something in a non-indexed multi-million rows fact table, the corresponding query will take a lot of time (and the typical end user doesn’t like to sit 5 minutes in front of his computer waiting for a report). If you had used indexes, you could have found your result in less than 5 (or 1, or 0.1) seconds.
I’ll answer the following three questions: Which kind of indexes can we use? On which tables/fields shall we use them? What are the consequences in terms of time (query time, index build time) and storage?
Which Kind Of Indexes Can We Use?
Oracle has a lot of index types available (IOT, Cluster, etc.), but I’ll only speak about the three main ones used in data warehouses.
B-tree Indexes
B-tree indexes are mostly used on unique or near-unique columns. They keep a good performance during update/insert/delete operations, and therefore are well adapted to operational environments using third normal form schemas. But they are less frequent in data warehouses, where columns often have a low cardinality. Note that B-tree is the default index type – if you have created an index without specifying anything, then it’s a B-tree index.
Bitmap Indexes
Bitmap indexes are best used on low-cardinality columns, and can then offer significant savings in terms of space as well as very good query performance. They are most effective on queries that contain multiple conditions in the WHERE clause.
Note that bitmap indexes are particularly slow to update.
Bitmap Join Indexes
A bitmap join index is a bitmap index for the join between tables (2 or more). It stores the result of the joins, and therefore can offer great performances on pre-defined joins. It is specially adapted to star schema environments.
On Which Tables/Fields Shall We Use Which Indexes?
Can we put indexes everywhere? No. Indexes come with costs (creation time, update time, storage) and should be created only when necessary.
Remember also that the goal is to avoid full table reads – if the table is small, then the Oracle optimizer will decide to read the whole table anyway. So we don’t need to create indexes on small tables. I can already hear you asking: “What is a small table?” A million-row table definitely is not small. A 50-row table definitely is small. A 4532-row table? I´m not sure. Lets run some tests and find out.
Before deciding about where we shall use indexes, let’s analyze our typical star schema with one fact table and multiple dimensions.
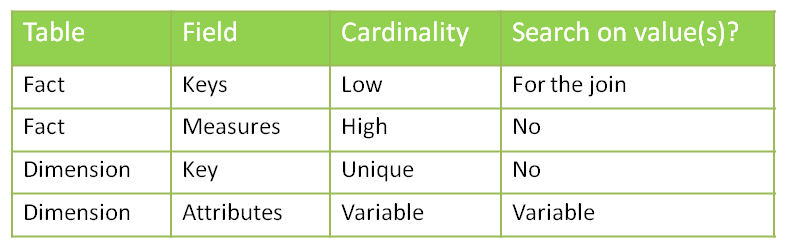
Star schema with one fact table and multiple dimensions
Let’s start by looking at the cardinality column. We have one case of uniqueness: the primary keys of the dimension tables. In that case, you may want to use a b-tree index to enforce the uniqueness. However, if you consider that the ETL preparing the dimension tables already made sure that dimension keys are unique, you may skip this index (it’s all about your ETL and how much your trust it).
We then have a case of high cardinality: the measures in the fact table. One of the main questions to ask when deciding whether or not to apply an index is: “Is anyone going to search a specific value in this column?” In this example I´ve developed I assume that no one is interested in knowing which account has a value of 43453.12. So no need for an index here.
What about the attributes in the dimension? The answer is “it depends”. Are the users going to do searches on column X? Then you want an index. You’ll choose the type based on the cardinality: bitmap index for low cardinality, b-tree for high cardinality.
Concerning the dimension keys in the fact table, is anyone going to perform a search on them? Not directly (no filters by dimension keys!) but indirectly, yes. Every query which joins a fact table with one or more dimension tables looks for specific dimension keys in the fact table. We have got two options to handle that: putting a bitmap key on every column, or using bitmap join keys.
Further Inquiries...
Are indexes that effective? And what about the storage needed? And the time needed for constructing/ refreshing the indexes?
We will talk about that next week on the second part of my post.