Some time ago we’ve seen how to create and maintain Oracle materialized views in order to improve query performance. But while materialized views are a valuable part of our toolbox, they definitely shouldn’t be our first attempt at improving a query performance. In this post we’re going to talk about something you’ve already heard about and used, but we will take it to the next level: indexes.
Why should you use indexes? Because without them you have to perform a full read on each table. Just think about a phone book: it is indexed by name, so if I ask you to find all the phone numbers of people whose name is Larrouturou, you can do that in less than a minute. However if I ask you to find all the people who have a phone number starting with 66903, you won’t have any choice but reading the whole phone book. I hope you don’t have anything else planned for the next two months or so.

It’s the same thing with database tables: if you look for something in a non-indexed multi-million rows fact table, the corresponding query will take a lot of time (and the typical end user doesn’t like to sit 5 minutes in front of his computer waiting for a report). If you had used indexes, you could have found your result in less than 5 (or 1, or 0.1) seconds.
I’ll answer the following three questions: Which kind of indexes can we use? On which tables/fields shall we use them? What are the consequences in terms of time (query time, index build time) and storage?
Which Kind Of Indexes Can We Use?
Oracle has a lot of index types available (IOT, Cluster, etc.), but I’ll only speak about the three main ones used in data warehouses.
B-tree Indexes
B-tree indexes are mostly used on unique or near-unique columns. They keep a good performance during update/insert/delete operations, and therefore are well adapted to operational environments using third normal form schemas. But they are less frequent in data warehouses, where columns often have a low cardinality. Note that B-tree is the default index type – if you have created an index without specifying anything, then it’s a B-tree index.
Bitmap Indexes
Bitmap indexes are best used on low-cardinality columns, and can then offer significant savings in terms of space as well as very good query performance. They are most effective on queries that contain multiple conditions in the WHERE clause.
Note that bitmap indexes are particularly slow to update.
Bitmap Join Indexes
A bitmap join index is a bitmap index for the join between tables (2 or more). It stores the result of the joins, and therefore can offer great performances on pre-defined joins. It is specially adapted to star schema environments.
On Which Tables/Fields Shall We Use Which Indexes?
Can we put indexes everywhere? No. Indexes come with costs (creation time, update time, storage) and should be created only when necessary.
Remember also that the goal is to avoid full table reads – if the table is small, then the Oracle optimizer will decide to read the whole table anyway. So we don’t need to create indexes on small tables. I can already hear you asking: “What is a small table?” A million-row table definitely is not small. A 50-row table definitely is small. A 4532-row table? I´m not sure. Lets run some tests and find out.
Before deciding about where we shall use indexes, let’s analyze our typical star schema with one fact table and multiple dimensions.
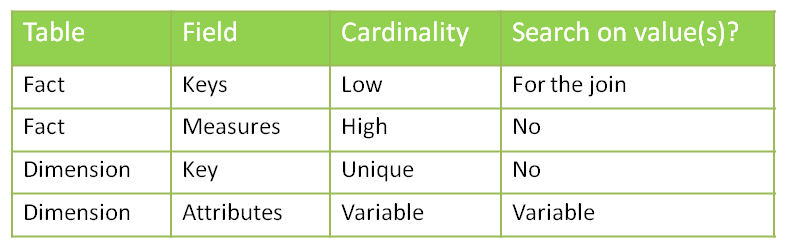
Let’s start by looking at the cardinality column. We have one case of uniqueness: the primary keys of the dimension tables. In that case, you may want to use a b-tree index to enforce the uniqueness. However, if you consider that the ETL preparing the dimension tables already made sure that dimension keys are unique, you may skip this index (it’s all about your ETL and how much your trust it).
We then have a case of high cardinality: the measures in the fact table. One of the main questions to ask when deciding whether or not to apply an index is: “Is anyone going to search a specific value in this column?” In this example I´ve developed I assume that no one is interested in knowing which account has a value of 43453.12. So no need for an index here.
What about the attributes in the dimension? The answer is “it depends”. Are the users going to do searches on column X? Then you want an index. You’ll choose the type based on the cardinality: bitmap index for low cardinality, b-tree for high cardinality.
Concerning the dimension keys in the fact table, is anyone going to perform a search on them? Not directly (no filters by dimension keys!) but indirectly, yes. Every query which joins a fact table with one or more dimension tables looks for specific dimension keys in the fact table. We have got two options to handle that: putting a bitmap key on every column, or using bitmap join keys.
Further Inquiries...
Are indexes that effective? And what about the storage needed? And the time needed for constructing/ refreshing the indexes?
We will talk about that next week on the second part of my post.