
image 1
Data mining, as per definition, is a discipline whose main aim is to discover patterns and most importantly, to predict and gain more knowledge on your data. This is done by combining different methods and approaches from artificial intelligence and statistics disciplines. One of the most common problems is how to build accurate and optimal classifier that given raw data helps us to build a model to classify future cases. There are many algorithms and methods available and we will refer in this blog article to the C4.5 which is available in the SAP Predictive Analytics tool. SAP Predictive analytics (SAP Infinite Insight) provides data mining capabilities that help many companies to anticipate customer behaviors and demands. SAP Predictive Analytics is very easy to use and very powerful, it can be downloaded here.
The C4.5 algorithm goal is to make decision trees based on datasets. Its first version came from ID3 algorithm which was developed by Ross Quinlan. Although C4.5 is highly popular, there are many other options like J48 and the extended C5.0.
How does it work?
By taking a group of examples, C4.5 builds the simplest decision tree (not necessarily binary) in order to classify new cases. It establishes the most important attribute as a base and adds new nodes by evaluating the importance of the following attributes.

image 2
In the example above, we can classify an object according to its attributes and get whether is a class A or a class B object. The leaf of the tree shows the result of the analysis.
Going into more detail, getting the shortest decision tree is a problem known in Computer Science as NP-Complete. This means basically that there is no way to find the most optimal solution for this problem in a reasonable time. And how is this possible? The order of the nodes is going to affect the size of the decision tree and this increases the complexity to a very high level. However, C4.5 uses a greedy approach to get a solution which works reasonably well. This solution relies on the concept of Information Entropy:
Note: The entropy measures the lack of homogeneity of an examples set
That is, the algorithm builds the tree by selecting the attribute with the smallest entropy possible. There are many references about the C4.5 operation and performance, but this may be something to cover in another post.
How can SAP help?
Data-mining capabilities are a must for many companies. They provide an insight for the future and analyst can anticipate events or behaviors that will improve the whole decision making procedure. On one hand, SAP Predictive analytics tool will provide the user interface to build predictive models and apply data mining procedures to forecast and analyze. It is built on top of SAP Lumira, therefore is graphic-based and very easy-to-use.
On the other hand, SAP HANA provides an extremely fast and powerful in-memory database. It would make sense that we can actually take advantage of this horse power and run the algorithm in HANA.
HANA’s Predictive Analysis Library (PAL) defines functions that can be used to perform predictive analysis algorithms.
Example
For this analysis, we will use the following raw data. The below table represents a list of customers from an insurance company and the last column defines if it is a fraudulent customer or not.
ID
POLICY
AGE
NATIONALITY
OCCUPATION
FRAUD
1
Home
24
Nation 1
Sales
No
2
Home
41
Nation 1
IT
No
3
Home
38
Nation 1
Sales
Yes
4
Home
62
Nation 1
Marketing
No
5
Home
51
Nation 2
Sales
No
6
Travel
33
Nation 2
Sales
No
7
Travel
46
Nation 2
IT
No
8
Travel
42
Nation 2
Marketing
No
9
Travel
21
Nation 2
Sales
No
10
Vehicle
44
Nation 2
IT
No
11
Vehicle
64
Nation 1
Sales
Yes
12
Vehicle
54
Nation 3
IT
No
13
Vehicle
26
Nation 3
Sales
No
14
Vehicle
44
Nation 3
Marketing
Yes
We would like to build a decision tree based on this data, that is going to help us to classify a customer to see if it’s probably fraudulent or not.
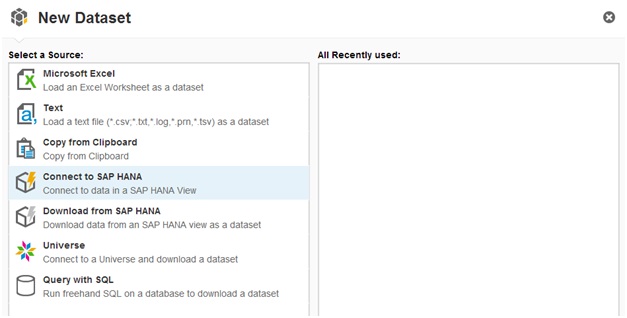
image 3
Let’s assume we have a model in HANA with this data available (check how to build a model find SAP reference guide http://www.saphana.com/docs/DOC-1074) in an Attribute View Called “PRED_SAMPLE”. So First we open SAP PA and click New Document and select Connect to SAP HANA.
After introducing host name and credentials, follow the process and select the view which contains the data to be analyzed and click on create.
Note: C4.5 is only available in HANA PAL and not in PA itself, so it will only be available when we are working with data in HANA.
After data has been loaded, we click on Predict to access the Predictive view. In the right panel we can select the available predictive algorithms and other procedures to use. HANA C4.5 should be available if we have established the connection successfully. We just have to double click and a node will be added in the composer.

image 4
We don’t need any data transformation since we assume the data has been prepared before.
Next step is to configure the execution, so we double click on the HANA C4.5 icon in the workflow and we will access the configuration panel. Once opened, in the Column Selection we select as Features the columns which are going to be the attributes of the decision tree:
Policy
Age
Nationality
Occupation
The value which is going to be the target of the classification is the column “FRAUD” (which is actually going to be the leaf of the tree). Therefore we specify it in the “Target Variable” field and click “Done”:
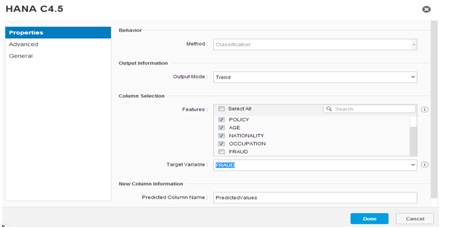
image 5
Now we simply click on “Run” and we will be redirected to the results view where we can get the decision tree design. Note that all leafs are providing a result for the analysis, while the nodes provide the probability of the result by going that way:
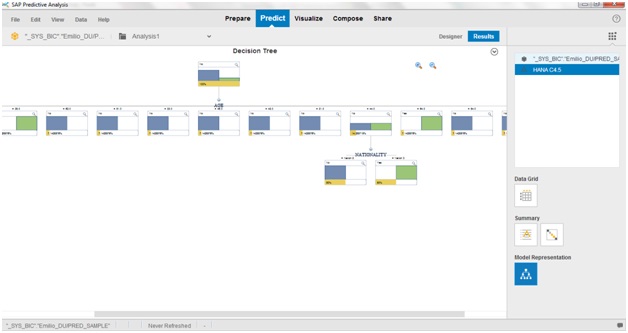
image 6
Some considerations
-> Check that you have HANA PAL installed on your HANA server
AFL (Application function library) includes PAL. We can open a SQL console and run the following command to check:
SELECT * FROM "SYS"."AFL_FUNCTIONS" WHERE SCHEMA_NAME = '_SYS_AFL' AND AREA_NAME = 'AFLPAL';
-> Check if the user used to log in HANA through PA has the role AFL_SYS_AFL_AFLPAL_EXECUTE granted. Same way, check in the Object Privileges tab if the procedures AFL_WRAPPER_GENERATOR and AFL_WRAPPER_ERASER are granted with Execute:
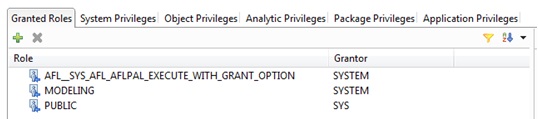
image 7
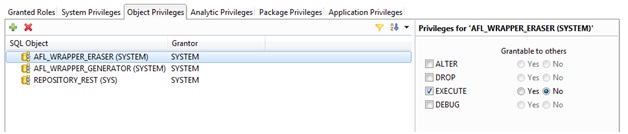
image 8