
When it comes to ETL development, optimal performance and scalability are key. In this article, we are going to cover our top 5 Clariba act·in | ETL Framework best practices to achieve this goal.
1. Structure is Key
During my career, I have seen many ETL jobs. One of the things that worried me the most were ETL jobs that had no structure. When you are using an ETL Solution such as SAP Data Services, you can use as many Workflows and Dataflows as you want, so use them!
It is easy to develop jobs with only few Workflows or Dataflows. However, these jobs are very difficult to maintain and to scale when developers have to make any modifications in the future. Instead, before getting hands on with your ETL think about possible modifications that may be required.
As defined in our Clariba act·in | ETL Framework we recommend following simple steps to ensure a best practice ETL structure.
a. Split your job in 4 phases: Administration, Starting, Staging, and Operational Data Store
The Administration phase will contain the administrative tables and variables which will contain the auditing information of the job (errors that may occur, notifications when the job starts, monitor if the job has to wait for another one to be executed...). The Starting phase will be for loading data from different sources to our system. In the Staging phase we will perform the required transformations and once completed load the data into your data warehouse in the Operational Data Store phase. We can create an additional phase at the end of our job to create aggregated tables for our different data marts – if required.
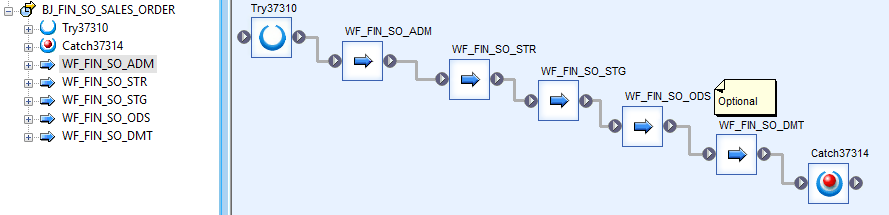
b. Always use a standard nomenclature:
An example would be: AA_BBB_CC_DDD_DESCRIPTION
AA is the type of object (BJ - Batch Job, DF - Dataflow, WF - Workflow, AF - Abap Data flow)
BBB would be the Datamart in which we are working (FIN - finance, PRO - Product ...)
CC the Job acronym
DDD will stand for the phase we are in (ADM - Administration, STR - Starting, STG - Staging, ODS - Operational Data Store)
And finally, use a brief concept description to indicate what the object is doing (you can use text boxes inside to add more information)
Here some examples:
Job - BJ_FIN_SO_SALES_ORDERS
Workflow - WF_FIN_SO_STR_LOAD_SOURCES
Data flow - DF_FIN_SO_STR_LOAD_SAP_SOURCE

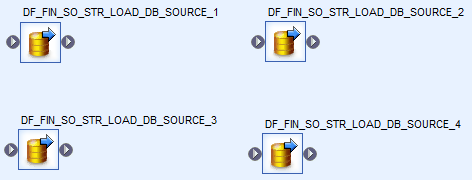
Finally, if you did the effort to follow the above examples, I would encourage you to also add a nomenclature to your queries and tables using the tips explained above.

This point is very useful when searching for specific objects in the central or local object library as they are sorted alphabetically.
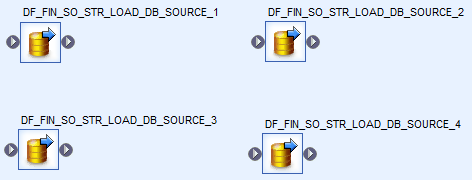
2. Parallelize
One of the key performance enhancers of SAP Data Services is parallelization. When used correctly it is an incredible way to make your jobs literally fly! However, use this capability wisely. You should only use parallelize when it makes sense to do so (e.g. if one data flow is dependent on another one, it makes no sense executing them in parallel).
Example of Data Flows working in parallel:
Example of Work Flows working in series:
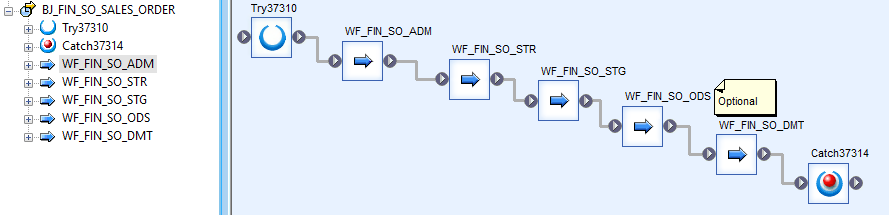
3. Pushdown
This topic, along with parallelization is top-notch when it comes to performance. The idea is taking advantage of the power of the database engine. This means that the logic applied in our data flows is delegated to the database instead of the job server.
However, everything has a cost and pushdown is not an exception. In this case, intensive research needs to be done in order to know which functions in SAP Data Services can be delegated to our database as this will increase the complexity of our job. But trust me, the effort is worth every hour spent. Luckily, there are many other blogs that cover this topic alone with much bigger depth!
So, how can we check if our dataflow is pushed down to the database? Easy! Inside the dataflow you want to check, select the tab Validation -> Display Optimized SQL. A window will appear. If the code generated is SQL with only a SELECT statement, then unfortunately your dataflow is not pushing down the code. However, if statements like INSERT, UPDATE, MERGE, UPSERT, etc are shown then, congratulations, you have successfully pushed down your transformations!
Find two examples with the same dataflow, one with pushdown and the other one without.
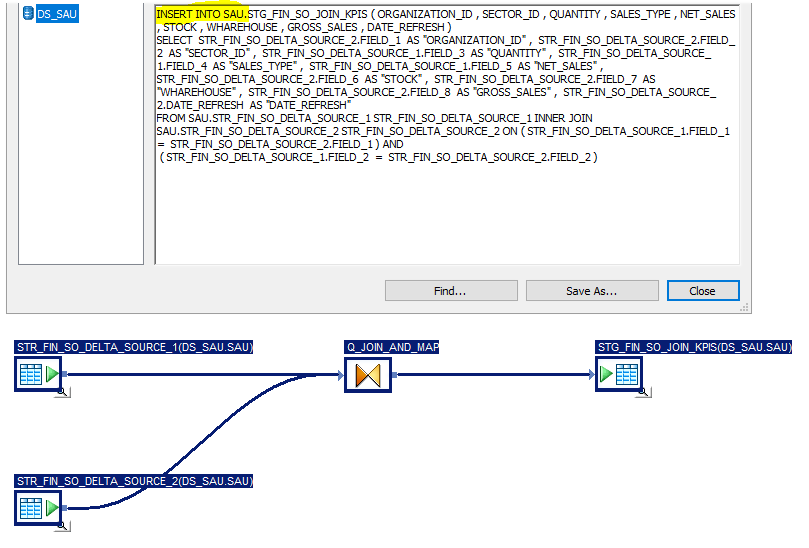
Dataflow with pushdown
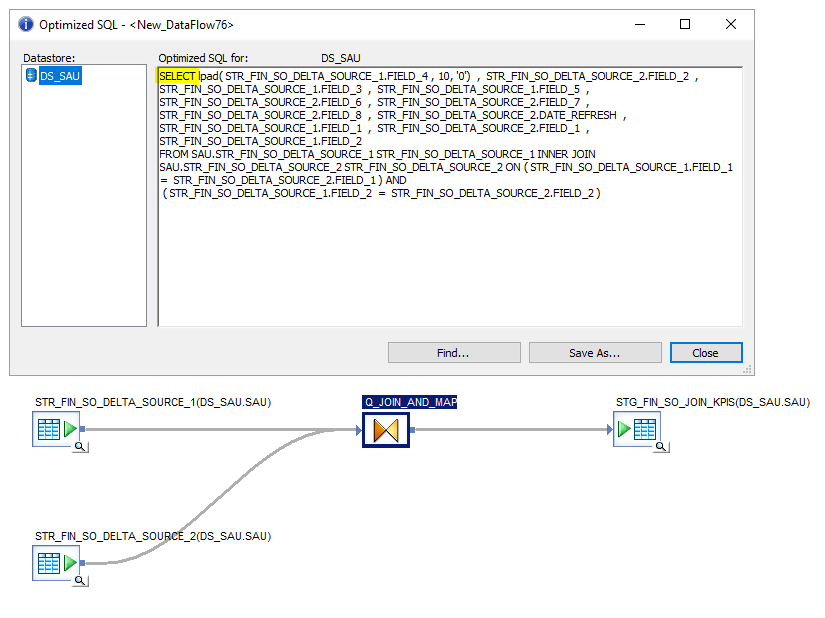
Dataflow without pushdown
4. Minimize Scripts for Transformations
Scripts are great when it comes to dealing with the initialization of variables and applying logic to our jobs. However, using scripts for transformations in the ETL is a widely common practice that is not ideal. We highly suggest to avoid this practice as much as possible due to the fact that scripts are not easily traceable.
Imagine a BIG job with several scripts and flows that insert/update/delete a FACT or DIM table. If we get an execution error, the fact of using scripts will not make it easy to find in which one we are getting the error due to the fact that SAP Data Services only shows you the line of code with the error and not where the error is in the job.
Moreover, think about it this way: If you are using an ETL tool, take advantage of its capabilities! One of its key functions is the ability to simplify and maintain complex logic by splitting and organizing it in workflows and dataflows.
5. Use Manual Tables to Parametrize
Last but not least, our last best practice tip for easy job maintenance is using manual tables for parametrization.
Imagine that in many of your jobs you are using standard filters and decodes. If one of those filters or decodes changes, you will have to change them manually everywhere! That creates a lot extra mind-numbing work and a task where mistakes are easily made!
Hence, we suggest to try and always apply this advice as much as possible. All the work described above would be solved with just one update!
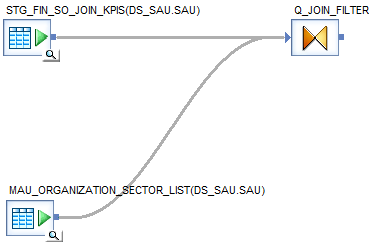
Example of a manual table used as a filter
Naturally, there are many more practices that we recommend as part of our Clariba act·in | ETL Framework. We hope that our article gave you some new insights and look forward to hearing your comments!