
During the implementation of Data Science Projects, we always face cases where we have to decide on the best method of implementation in order for it to be integrated with the pipeline smoothly. The goal is to achieve the most simplistic implementation as the overall design is always complex. We focus on to simplifying our approaches as much as possible so we can keep track of all the steps and modify them easily with minimum implementation/modification time.
In today’s post, we will discuss a case we have shown before but in more detail. We will teach you how use Python to simplify a step with a powerful Python & SAP Hana Integration Library called HDBCLI.
First, let us put things into context. The case that we faced during the implementation was having some NULLs in the Nationality Column in each of the independent geographical areas. These NULLs represent about 5% -> 15% of the overall data volume. Therefore, as a quick approach, we decided to apply a re-distribution method that can take the full population and its Nationality distribution and re-apply it on the NULLs. You can find more details about the logic approach here.
It would be difficult to apply this solution using a SAP HANA SQL approach, thus we decided to go with a Python implementation for this step, and there would be two methods to achieve this:
Method 1:
Export the data into a Comma Separated Values file (CSV) using SAP Data Services.
Load the CSV with the Python, apply our solution, export it into another CSV.
Load the data from the CSV into the SAP HANA Table with SAP Data Services.
Method 2 (Currently Used):
Install HDBCLI Library in Python.
Connect directly to SAP HANA using our Credentials and the IP address of the server.
Load the table directly using Structured Query Language (SQL) by a cursor in Python into a Pandas Data Frame.
Apply our solution, export the data into a CSV.
Load the data into SAP HANA Table using SAP Data services, it will update the tables that had been modified from NULLs to a real value automatically.
In order to minimize the number of files and simplify the approach, we decided to use the second method. We tried to load the data directly into SAP HANA through HDBCLI using Update Table Queries but, due to the connection and number of rows, it was very slow. Therefore, when loading back into the table, we will be using ETL (extract, transform, and load). But in retrieving values from SAP HANA, we can simply reply on HDBCLI as it is much faster and removes the need for flat files.
First of all, we created a class that is responsible for any database communication and we called it Query Provider. This class takes standard input to connect to any server, a screenshot of the code is posted below:
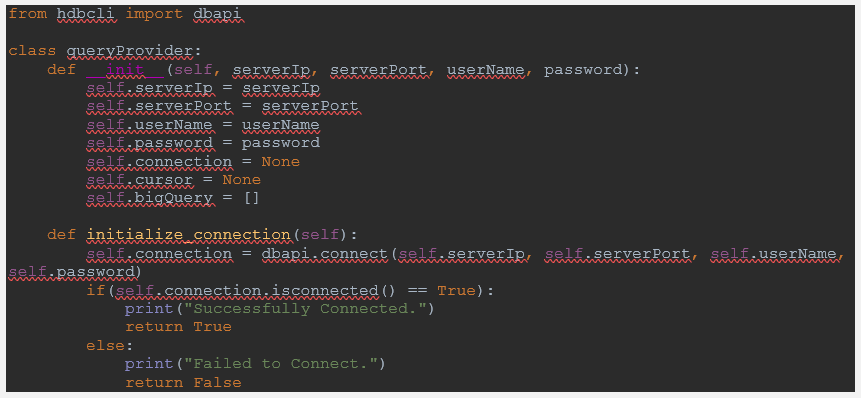
Now, using this class, we can simply connect to any SAP HANA Server. Once we initialize the connection, we need to retrieve the table that we require using the following sample function:

As you can see, the approach is very simple. We just copy / paste our query as a string and execute the query using the cursor and, once we get the elements, we can close the cursor and return the elements that we selected. The reason we posted the fetchall() result in a variable is that sometimes we would want to do some modifications before returning the table.
Now that we have our table, that has all the data we need, we proceed to insert it into a Pandas Data Frame (DF for short). A pandas DF acts like a table, it has columns and we can call a column by its name and apply any modifications we need to it like a data base, as well as the following functions such as:
Aggregations
Joins
Unions
The following code shows how we can take the result of a cursor retrieved table and insert it into a Pandas DF:
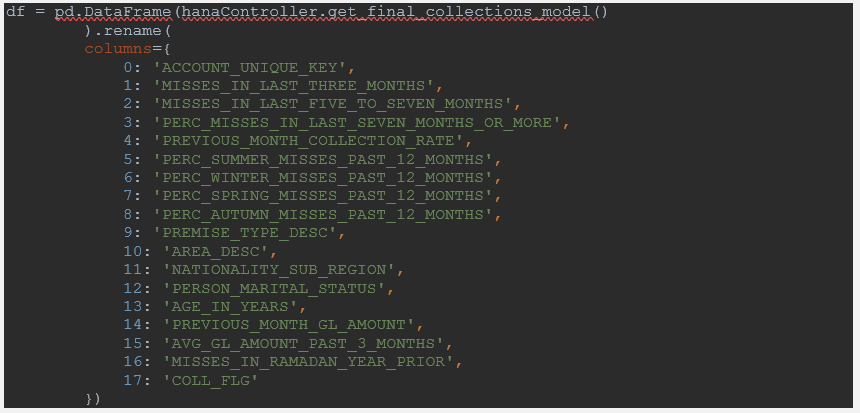
This is the code we used when we were preparing to train our model. You can see that we called the class that we created earlier HanaController, then the name of the function that retrieves the table. When the table is retrieved, the columns are named by their indexes: 0,1,2,3. Therefore, we need to rename them to match the database so we can work appropriately without mixing up the columns. And we can do that by simply calling the. Rename() function.
Since we already have our data in tabular format and columns are named correctly in Python, we can apply any complex / specific logic to it. As you will see, complex redistribution based on the area will be very simple as in Python we can use a very strong linear Algebra library called NumPy. It has the following function:

The previous function, np.random.choice, makes a choice based on the probability of the occurrences of each of the elements in the list, so we would pass to the function the following values:
List of Elements: [“Egypt”, “India”, “KSA”].
Probability of Occurrences (“Needs to add up to 1”): [0.6, 0.2, 0.2].
This way, on each iteration, the function will make a pick based on the probability of the unique element, keeping the integrity of the distribution intact in the process. Please note that we have posted this data in a new column and did not overwrite the data in the original Nationality Column. The new column is called Sub_Region_Distributed.
Now that we have our new Column in the Pandas DF, we can print it with one line into a file that we will use in order to load it with ETL Data Services Tool into our SAP HANA Table. The following function is used to print the file:

Finally, we need to integrate it with the pipeline. The following image is a screenshot of the overall pipeline:
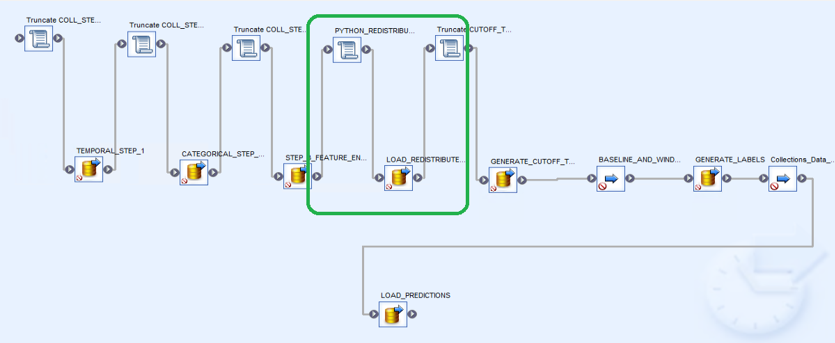
The area highlighted in green is where we have integrated our Python step. First, we run the Python script using the following function: #exec('cmd','python PATH\PYTHON_FILE.py',8 ); Then we load the file into our HANA Database.
This is one approach to the problem that works very well and is extremely beneficial. During an implementation of a Data Science project, you will always face challenges and problems where a solution needs to be effective and efficient. If a solution takes days or weeks to be implemented, then it might not be the best one. We always keep our minds open to all kinds of tools that can enable us to solve problems in the best manner possible. This is an empiric process that offers great outcomes.
Let us know if you have any comments or suggestions!