
The impact and value of data are key issues for many companies. Information volume grows exponentially every day and that growth is forecast to continue. It is estimated that companies will create 60% of information worldwide by 2025.
Information is therefore a very valuable asset for any company, essential for decision-making and actions. But it loses all its value if the quality of the data can’t be guaranteed.
Data quality is a set of processes by which data is processed to ensure its reliability and rigor.
In a post COVID-19 world, trust has become a fundamental asset, and companies that are able to generate a trustworthy relationship with their customers will return to uninterrupted growth much faster.
The reliability of their data, therefore, becomes a decisive factor for the future of the company and its ability to maintain that relationship of trust with customers.
1. Overview of the process
At Clariba, we know the importance of quality in ensuring the best results. For this reason, we have recently created a process with one of our clients in which we automate the quality assurance of their data. It’s easy to implement and simple to use.
The entire process is based on a series of configuration rules which indicate the tables and fields to which the quality assurance is to be applied, and through a series of procedures, it performs cleaning and homogenization of the data.
First, the data is read and the previously analysed and defined cleaning actions are applied, where conditions such as changing the data type or deleting, modifying or replacing any character can be established.
Once corrected, homogenization is applied to provide the data with the final reliability and robustness required.
Finally, we validate that this data is correct to guarantee quality. For this reason, we analyse each item of data to verify that the cleaning and homogenization is accurate, and if a failure is detected, we record that detailed failure to be able to review the case and correct it.
Failures can occur because homogenization is done through relationship crossovers to retrieve the correct value. If any of these crosses fails, it is usually because there is a new causal relationship, and this must be defined to correct it.
The entire structure of this process is detailed below in a step-by-step guide.
2. Step by step guide
The first step is to create the main cleaning configuration table, where we detail which ETL processes the data quality will be applied to. In addition, the source table is indicated, to retrieve the names and types of fields, the destination table, where the cleaned data will be stored, the name of the table that will be generated to apply the actions to each of the fields in the origin table and, finally, the name of the table where the information on which field is to be applied to which cleaning action is stored.

Table 1: main cleaning configuration table
Once we have the first complete configuration table an automated procedure reads the table and creates as many cleaning tables as there are defined in the configuration. These will be the tables that are generated for, via predefined parameters, the cleaning actions that we indicate should be applied to them. By default, all the parameters are set to "0", and for the process to apply a specific action, the value must be updated to "1".
The cleaning tables will look like this:

Table 2: table generated to apply cleaning
When cleaning the data, it is useful to establish a standard in each type of field to facilitate homogenization. For example, all fields of type varchar must be capitalized with spaces, accents, or special characters removed. Or if it is a date type, convert all dates to the same format.
In addition, the master list of actions to be applied must be configured. This table specifies the name of the cleaning action, and the functions in SQL language to apply to the fields. For certain functions, the field may need to be read only once or multiple times.
The following table shows two examples:

Table 3: cleaning functions master table
Once all these tables have been established, the next step is to generate the action table via which all the changes will be applied to the selected fields.

Table 4: final cleaning table
Finally, the target table of Table 1 is read, and the information is cross referenced with the action table to return all the clean data before starting the next process.
The next step is homogenization. As with the cleaning process, we first must define the main configuration table. In this case, we have the details of the process, the source table, and the destination table.

Table 5: main homogenization table
Along with the main table, there is another table with details of which fields are going to be homogenized, and within which tables it is going to retrieve the correct value.

Table 6: homogenization table
It is necessary to have the homogenization tables with the highest number of cases for each of the fields. That is, through relationships, a code is retrieved that is used to make a last match with the correct value.
An illustrative case is the province field shown below, where the same province can be reported to us in different ways. With cleaning, we capitalize and eliminate spaces, accents, and special characters in the province name.
First, we cross reference the information by retrieving the identifier, and then return from the master table the correct value corresponding to that identifier.
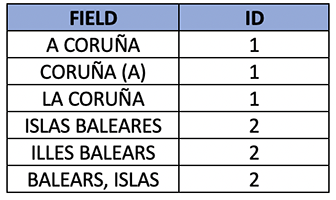
Table 7: relations table

Table 8: province master table
At this point, the data is almost ready to work with, but first we must validate that the quality of the data is correct. To do this, we cross-reference the data with the master tables of each standardized field and check the values are correct.
If there is data that could not be standardized, a table is kept where all the failures are recorded, containing detailed information on the process to which it corresponds, the field and value that could not be standardized, and the date.
In the cases in which it is detected that a value could not be standardized, it must be entered in the homogenization table so that the next time it can be processed without errors.
Finally, the entire process flow is visually detailed:

As we’ve seen, building a data quality process is relatively straightforward. Even though it requires an appreciable amount of time and resource to set up, the value added to the business by being able to ensure the quality, reliability and homogeneity of all data far outweighs this initial cost.
And with the expansive growth of data produced by organisations of all sizes continuing to increase, there’s never been a better time to get your house in order when it comes to data quality. Putting the correct systems in place now will save much greater effort in future.
If you’d like to learn more about setting up a quality assurance process for data handled and stored by your organisation, we’d be happy to talk through your options. Contact us via the details below to schedule a meeting.