
Imagen 1
Data mining, as per definition, is a discipline whose main aim is to discover patterns and most importantly, to predict and gain more knowledge on your data. This is done by combining different methods and approaches from artificial intelligence and statistics disciplines. One of the most common problems is how to build accurate and optimal classifier that given raw data helps us to build a model to classify future cases. There are many algorithms and methods available and we will refer in this blog article to the C4.5 which is available in the SAP Predictive Analytics tool. SAP Predictive analytics (SAP Infinite Insight) provides data mining capabilities that help many companies to anticipate customer behaviors and demands. SAP Predictive Analytics is very easy to use and very powerful, it can be downloaded here.
El objetivo del algoritmo C4. 5 es crear árboles de decisión basados en conjuntos de datos. Su primera versión vino del algoritmo ID3 que fue desarrollado por Ross Quinlan. Aunque C4. 5 es muy popular, hay muchas otras opciones como J48 y el C5 extendido. 0.
¿Como funciona?
Tomando un grupo de ejemplos, C4. 5 construye el árbol de decisiones más simple (no necesariamente binario) para clasificar nuevos casos. Establece el atributo más importante como base y añade nuevos nodos evaluando la importancia de los siguientes atributos.

Imagen 2
En el ejemplo anterior, podemos clasificar un objeto de acuerdo a sus atributos y obtener si es una clase A o un objeto de clase B. La hoja del árbol muestra el resultado del análisis.
Más detalladamente, obtener el árbol de decisiones más corto es un problema conocido en la informática como NP-completo. Esto significa básicamente que no hay manera de encontrar la solución más óptima para este problema en un tiempo razonable. ¿Y cómo es esto posible? El orden de los nodos va a afectar el tamaño del árbol de decisión y esto aumenta la complejidad a un nivel muy alto. Sin embargo, C4. 5 utiliza un enfoque codicioso para obtener una solución que funcione razonablemente bien. Esta solución se basa en el concepto de Entropía de Información:
Nota: La entropía mide la falta de homogeneidad de un conjunto de ejemplos
Es decir, el algoritmo construye el árbol seleccionando el atributo con la entropía más pequeña posible. Hay muchas referencias sobre la operación y el rendimiento de C4. 5, pero esto puede ser algo que cubrir en otro post.
¿Cómo puede ayudar SAP?
Las capacidades de minería de datos son una necesidad para muchas empresas. Proporcionan una visión para el futuro y el analista puede anticipar eventos o comportamientos que mejorarán el proceso de toma de decisiones. Por un lado, la herramienta SAP Predictive Analytics proporcionará la interfaz de usuario para construir modelos predictivos y aplicar procedimientos de minería de datos para pronosticar y analizar. Está construido sobre SAP Lumira, por lo tanto es basado en gráficos y muy fácil de usar.
Por otro lado, SAP HANA proporciona una base de datos en memoria extremadamente rápida y potente. Tendría sentido que realmente podamos aprovechar esta potencia de caballos y ejecutar el algoritmo en HANA.
La Biblioteca de Análisis Predictivo (PAL) de HANA define funciones que pueden usarse para realizar algoritmos de análisis predictivo.
Ejemplo
Para este análisis, utilizaremos los siguientes datos brutos. La siguiente tabla representa una lista de clientes de una compañía de seguros y la última columna define si es un cliente fraudulento o no.
IDENTIFICACIÓN
POLÍTICA
AÑOS
NACIONALIDAD
OCUPACIÓN
FRAUDE
1
INICIO
24
Nación 1
Ventas
No
2
INICIO
41
Nación 1
ESO
No
3
INICIO
38
Nación 1
Ventas
Sí
4
INICIO
62
Nación 1
Márketing
No
5
INICIO
51
Nación 2
Ventas
No
6
Viajar
33
Nación 2
Ventas
No
7
Viajar
46
Nación 2
ESO
No
8
Viajar
42
Nación 2
Márketing
No
9
Viajar
21
Nación 2
Ventas
No
10
VEHÍCULO
44
Nación 2
ESO
No
11
VEHÍCULO
64
Nación 1
Ventas
Sí
12
VEHÍCULO
54
Nación 3
ESO
No
13
VEHÍCULO
26
Nación 3
Ventas
No
14
VEHÍCULO
44
Nación 3
Márketing
Sí
Nos gustaría construir un árbol de decisiones basado en estos datos, que va a ayudarnos a clasificar a un cliente para ver si es probablemente fraudulento o no.
Imagen 3
Let’s assume we have a model in HANA with this data available (check how to build a model find SAP reference guide http://www.saphana.com/docs/DOC-1074) in an Attribute View Called “PRED_SAMPLE”. So First we open SAP PA and click New Document and select Connect to SAP HANA.
Después de introducir el nombre del host y las credenciales, siga el proceso y seleccione la vista que contiene los datos a analizar y haga clic en crear.
Nota: C4. 5 solo está disponible en HANA PAL y no en PA, por lo que sólo estará disponible cuando trabajemos con datos en HANA.
Después de cargar los datos, hacemos clic en Predict para acceder a la vista Predictive. En el panel derecho podemos seleccionar los algoritmos predictivos disponibles y otros procedimientos a utilizar. HANA C4. 5 debería estar disponible si hemos establecido la conexión correctamente. Sólo tenemos que hacer doble clic y un nodo se agregará en el compositor.

Imagen 4
No necesitamos ninguna transformación de datos, ya que suponemos que los datos se han preparado antes.
El siguiente paso es configurar la ejecución, así que hacemos doble clic en el icono HANA C4. 5 en el flujo de trabajo y accederemos al panel de configuración. Una vez abierto, en la Selección de Columna seleccionamos como Características las columnas que van a ser los atributos del árbol de decisión:
POLÍTICA
AÑOS
NACIONALIDAD
OCUPACIÓN
El valor que va a ser el objetivo de la clasificación es la columna "FRAUD" (que en realidad va a ser la hoja del árbol). Por lo tanto, lo especificamos en el campo "Variable de destino" y hacemos clic en "Hecho":
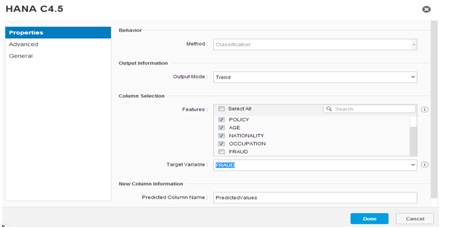
Imagen 5
Ahora simplemente hacemos clic en "Ejecutar" y seremos redirigidos a la vista de resultados donde podremos obtener el diseño del árbol de decisión. Tenga en cuenta que todas las hojas están proporcionando un resultado para el análisis, mientras que los nodos proporcionan la probabilidad de que el resultado de ir de esa manera:
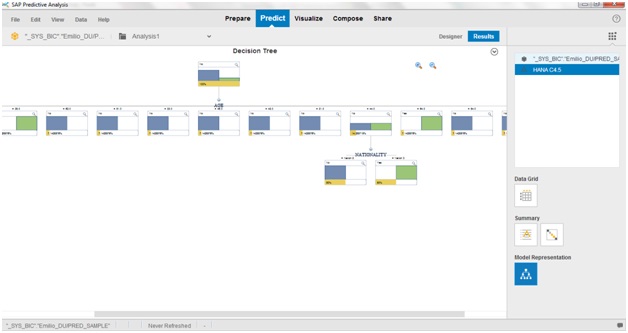
Imagen 6
Algunas consideraciones
-> Comprueba que tienes HANA PAL instalado en tu servidor HANA
AFL (biblioteca de funciones de aplicación) incluye PAL. Podemos abrir una consola SQL y ejecutar el siguiente comando para comprobar:
SELECT * FROM "SYS"."AFL_FUNCTIONS" WHERE SCHEMA_NAME = '_SYS_AFL' AND AREA_NAME = 'AFLPAL';
-> Check if the user used to log in HANA through PA has the role AFL_SYS_AFL_AFLPAL_EXECUTE granted. Same way, check in the Object Privileges tab if the procedures AFL_WRAPPER_GENERATOR and AFL_WRAPPER_ERASER are granted with Execute:
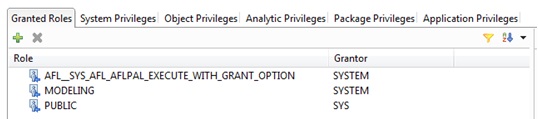
Imagen 7
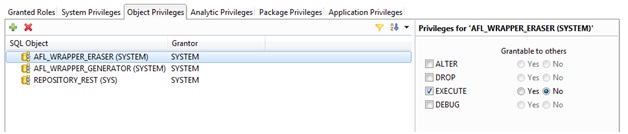
Imagen 8