
Si no ha leído las publicaciones anteriores de esta serie, le recomendamos que las revise antes de continuar, ya que cada publicación se basa en los temas tratados en la anterior. En la Parte 1 cubrimos la creación de un entorno de desarrollo, en la Parte 2 analizamos las estructuras y filas de tablas, y en las Parte 3 y Parte 4 mostramos cómo crear escenarios federados.
En esta quinta sesión, seguiremos trabajando con calculation views, específicamente aprendiendo a mejorarlas para consultas que utilizan diferentes técnicas, por ejemplo, Union Pruning y Static Cache.
Para los siguientes ejercicios, usaremos solo una instancia. Pero las mismas técnicas también se pueden desarrollar dentro del escenario federado que creamos en las publicaciones anteriores.
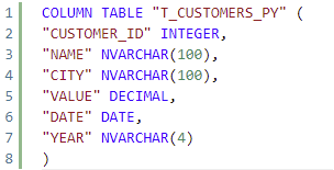
En nuestro espacio de trabajo tendremos 2 tablas, T_CUSTOMERS_CY que contiene datos de 2022 y T_CUSTOMERS_PY que contiene datos de años anteriores. Puedes ver las definiciones a continuación:



1. 1. Creación de calculation view
Para empezar, nuestro objetivo es tener todos los datos en una misma calculation view, para ello la estructura de la calculation view se construirá como se muestra a continuación:

Estamos incluyendo las tablas involucradas como una proyección y usando el nodo de unión para obtener todos los datos en una sola tabla. En el nodo de unión, puede mapear las columnas una por una, pero también es posible delegar esta tarea a SAP HANA Cloud usando la siguiente opción:

NB: Verifique que las fuentes de datos estén bien definidas antes de usar esta opción.
El siguiente paso en esta definición es crear una constante para diferenciar las diferentes fuentes de datos en la salida del nodo U_CUSTOMERS. Para hacer esto, haga clic en el botón '+':

Una vez que haga clic en este botón, se abrirá un menú de configuración. Seleccione un nombre adecuado, NVARCHAR como tipo de datos y una longitud adecuada. Vea un ejemplo a continuación donde el valor constante para 2022 es ‘CURRENT’ y para el resto de los años es ‘PREVIOUS’:

Este valor será necesario más adelante, cuando usemos el artefacto Analytic Privilege y será un aspecto crucial de la seguridad de la vista.
NB: si tiene un gran conjunto de datos y tiene la intención de acceder solo a una parte de ellos, también es útil filtrar los datos que desea usar para mejorar el rendimiento.
Ahora haga un build sobre la calculation view para asegurarse de que todo esté configurado correctamente. Puede obtener una vista previa de los datos en este punto haciendo clic derecho en el objeto en el área de trabajo del proyecto y seleccionando la opción "Data Preview", como se muestra aquí:Data Preview

También podemos realizar una vista previa de datos como una función SQL. En este caso, el código que se usaría sería como el que se muestra aquí:

2. Static Cache
Otra técnica para minimizar la transferencia de datos necesaria es hacer uso del almacenamiento en caché. El almacenamiento en caché es una técnica en la que almacena los datos tal como están en este momento y si llega otra consulta y el tiempo de almacenamiento aún es válido, los datos se toman de este almacenamiento intermedio.
El almacenamiento en caché solo tiene sentido si ya ha preprocesado sus datos, por lo que la idea es almacenar los datos después de este preprocesamiento. Por ejemplo, si los usuarios suelen trabajar con solo unas pocas columnas, tiene sentido definir la memoria caché para estas columnas.
Habilitar esta opción es muy sencillo. En SAP HANA Cloud, regrese a Business Application Studio y haga clic en su nodo de Semantics. Vaya a ‘View Properties’ > ‘Static Cache’, seleccione la opción ‘Enable Cache’ y modifique el período de retención al deseado. Después de eso, defina el caché, en este caso de ejemplo, supongamos que los usuarios suelen usar todas las columnas excepto el año actual:

Cuando finalice la configuración, simplemente vuelva a desplegarla vista para completar el proceso.
3. Conclusión
En los ejercicios de hoy, cubrimos cómo realizar un modelado de datos simple en una calculation view con un nodo de unión y aprendimos cómo optimizar su rendimiento utilizando la técnica de almacenamiento en caché. Todo lo que queda es asegurarnos de que hemos protegido los datos involucrados, que trataremos en nuestro próximo y último artículo de esta serie de SAP HANA series - Parte 6, así que esté atento al blog de Clariba para obtener más actualizaciones.
Para finalizar con ese desarrollo y como último paso, solo resta la seguridad necesaria sobre los datos contenidos, consulta la siguiente parte para saber cómo hacerlo.
