
La ingeniería de características es un paso crucial en el proceso de construcción en el desarrollo del aprendizaje de máquinas, ya que el algoritmo utilizará las características como predictores.
Por lo tanto, es aconsejable priorizar la creación y la optimización de nuestras características para asegurarnos de que comencemos con un modelo de datos robusto, lo que dará como resultado que nuestro modelo de aprendizaje automático obtenga buenos resultados.
Existen muchos desafíos que pueden surgir durante la preparación de las funciones. Nuestros datos deben de comenzar con un formato específico, pero necesitamos cambiar ese formato y convertir la forma en que están estructurados para que el algoritmo de aprendizaje automático los entienda.
Un problema común es el malentendido del caso de uso comercial por falta de experiencia, que a menudo resulta en la construcción de características débiles.
Esta publicación se concentrará en cómo abordar las características en general y brindará un ejemplo de los resultados después de que hayamos construido nuestras características y su efecto en el modelo.
Ejemplo: Transacciones financieras
Nuestro ejemplo se centra en la facturación y el cobro en una empresa de servicios públicos ficticia.
Para simplificar las cosas, solo discutiremos datos basados en una tabla. No intentaremos discutir el modelo de datos completos, ya que habría varias tablas unidas, lo que lo hace demasiado complejo para nuestros propósitos.
Analizando la tabla
La tabla principal que analizaremos es la tabla de transacciones financieras. Esta tabla contiene información sobre diferentes tipos de transacciones para cada cliente. Hay 6 tipos de transacciones:
BS: segmento de facturación
BX: Segmento de facturación cancelado
PD: Segmento de pago
PX: Segmento de pago cancelado
AD: Ajuste
AX: Ajuste cancelado
Each Billing Segment ID is linked to a unique transaction so we can track the different types of transactions per Billing Segment. So, for simplification purposes, we will construct this table based on the important columns:

Caso de uso comercial
Ahora tenemos que revisar nuestro caso de uso comercial para que comprendamos cómo podemos remodelar los datos actuales en un nuevo modelo que sirva para nuestro propósito y sea fácilmente digerible por el Modelo de Aprendizaje Automático.
Nuestro caso de uso:
Aumente la frecuencia de pagos puntuales de facturas, disminuyendo la tasa de cobro de servicios públicos (electricidad y agua)
Descripción del caso de uso:
Al comienzo de cada mes, nuestra empresa factura a los clientes su consumo de electricidad y agua del mes anterior.
Necesitamos mejorar el flujo de efectivo y optimizarlo. Actualmente tenemos clientes que se retrasan en sus pagos, lo que resulta en picos y valles en el flujo de efectivo. Entonces nuestro objetivo es estabilizar el flujo de efectivo.
Idealmente, queremos que los clientes siempre paguen a tiempo. Sin embargo, este no siempre es el caso, y la solución actual que estamos aplicando es que enviamos una lista de "usuarios" que actualmente están retrasados al departamento de cobros, comenzando el proceso de cobranza para esos usuarios. Este método tiene varios defectos:
La lista contiene usuarios actualmente retrasados. No estamos teniendo en cuenta el patrón de comportamiento de cada usuario para predecir si ese usuario se retrasará o no se implementará un proceso de cobros preventivo para minimizar los retrasos.
Esta lista no toma en cuenta otros factores. Por ejemplo: después de implementar nuestra solución, en lugar de que el departamento de cobros obtenga una lista de 2,000 usuarios retrasados, les enviaremos una lista de los 1,000 usuarios críticos por cantidad demorada. De esta manera, podemos asegurar que estamos aplicando nuestra solución a los usuarios que más afectan el flujo de efectivo.
El proceso de recopilación a veces lleva más de dos semanas. Por lo tanto, si podemos predecir los usuarios que se retrasarán y comenzar el proceso de recopilación, podemos abordar el problema incluso antes de que surja.
Ingeniería de características: ¿Cómo comenzar?
Uno de los mejores trucos para comenzar nuestra ingeniería de características es mirar nuestra definición inicial del caso de uso. Si se define correctamente, podemos derivar nuestro punto de partida (y una de las características más fuertes).
Nuestro caso de uso es el siguiente:
Aumente la frecuencia de pagos puntuales de facturas, disminuyendo la tasa de cobro de servicios públicos (electricidad y agua)
Ahora, a partir de la definición de caso de uso anterior, podemos ver que estamos tratando de disminuir la tasa de recolección, pero ¿cuál es la tasa de recolección? Definimos la tasa de cobro como:
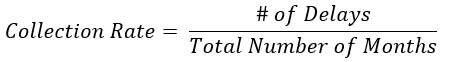
Esta es una de las métricas que vemos y queremos optimizar, idealmente para disminuir la tasa de recolección por usuario. Entonces, primero debemos identificar cómo verificamos si un usuario es elegible para la recolección.
La respuesta a eso es:
Si un usuario no ha pagado la factura del mes anterior al final del mes actual, entonces el usuario es elegible para cobros.
Entonces, por ejemplo, un usuario tiene una factura de $ 1,000 para enero. Recibirá la factura a principios de febrero.
Si el usuario no ha pagado esta factura a fines de febrero, entonces el usuario es elegible para ingresar a las colecciones.
Con este conocimiento, podemos comenzar a construir nuestro nuevo modelo de datos base, llamado tabla de tiempos de corte. Esta tabla está construida de la siguiente manera:Cut Off Times
tenemos el comportamiento mensual del usuario desde que abrió una cuenta con nosotros.
Verificamos el saldo de la cuenta de ese usuario, si es negativo o “0”, esto significa que el usuario no nos debe dinero y no es elegible para cobros. Sin embargo, si el saldo es mayor de $ 200, el usuario es elegible para ingresar a los cobros, ya que el usuario lleva más de $ 200 de deuda al próximo mes. Esta es una de las métricas que vemos y queremos optimizar, idealmente para disminuir la tasa de recolección por usuario. Entonces, primero debemos identificar cómo verificamos si un usuario es elegible para la recolección.
La estructura de la tabla de tiempos de corte es la siguiente:Cut Off Times
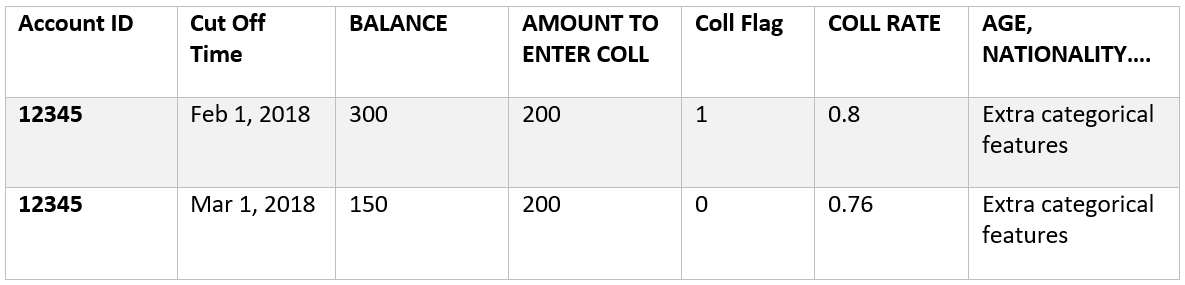
Explicación de los datos en esta tabla:
Identificación de cuenta
Tiempo de corte: este es el momento de hacer la predicción
Saldo: esta es la suma del saldo de la cuenta al final del mes en que cae el tiempo límite, por lo que si el tiempo límite es el 1 de febrero de 2018, el saldo es al 28 de febrero de 2018
Cantidad para ingresar a colección: comparamos el saldo con este valor
Indicador de colección o “Coll Flag”: esta es el indicador de colección, esto es = 1 si el saldo excede la cantidad para ingresar colección
Tasa de colección: La tasa de cobro a partir del mes actual. Esto no tiene en cuenta el indicador de colección del mes actual, ya que esto causaría una fuga de datosdata leakage
Edad, nacionalidad, ubicación, etc: estas son características categóricas extraídas de otras fuentes de datos
Mejorando el modelo de datos
Ahora que tenemos un modelo de datos sólido, podemos llevar esto un paso más allá y mejorarlo. Si capacitamos al modelo en los datos actuales, podría ser problemático como:
La cantidad de datos es mucho mayor de lo requerido.
El modelo probablemente se ajuste demasiado a la cantidad de detalles que tenemos actualmente, ya que nuestras características no están diseñadas correctamente.
Entonces, demos un paso atrás y analicemos el problema actual.
Tenemos el comportamiento mensual (etiquetado por la columna “Indicador de colección o Coll Flag"). Sin embargo, cuando analizamos el comportamiento humano, no necesitamos poner el mismo énfasis en todos los meses anteriores (ya que el comportamiento humano cambia a través del tiempo en función de muchos factores diferentes).Coll Flag
Lo que podemos hacer es comenzar otro paso de reconstrucción y agregar nuevas características. El primer paso que podemos tomar es agregar el modelo de datos actual a nivel de la identificación de cuenta. De esta manera comprimiremos nuestros datos masivamente, lo que dará como resultado un modelo mucho más rápido y robusto con los valores puros que queremos presentar a nuestro Modelo de aprendizaje automático.
El primer ejemplo de cómo podemos contar con el ingeniero de características con énfasis en duraciones de tiempo específicas es convirtiendo la columna Indicador de colección en 4 características:
% de faltas de pago en los últimos 3 meses
% de faltas de pago de 4 a 7 meses.
% de faltas de pago de 7 a 12 meses.
% de faltas de pago de 12 meses a ∞
Y este enfoque tiene un par de beneficios:
El modelo dará como resultado que la característica más importante de todas esas 4 características es el % de fallas en los últimos 3 meses, ya que contiene el patrón de comportamiento más reciente del usuario y entre más retrocedemos en el tiempo, menos relevante se vuelve. Esto ilustra por qué la capacitación en los datos completos sin corregir las características y abordarlos manualmente en función del conocimiento y la lógica del dominio dará como resultado un modelo débil.
Converting this into a % will solve the problem of having a variance between users where some may have 4 years of data and some users have 2 years of data.
Como puede ver hasta ahora, ya que este es un problema de colecciones, nos estamos concentrando en las características temporales y no tanto en las categóricas. Sin embargo, como cada usuario muestra un patrón individual, su ubicación y nacionalidad también pueden desempeñar un papel.
Mejoras adicionales
Ahora tenemos un modelo de datos bastante robusto. Sin embargo, aún podemos hacer más. Agreguemos características de estacionalidad para mejorar aún más nuestro modelo. Entonces, podemos agregar 4 características adicionales:
% de faltas de pago en primavera en los últimos 12 meses
% de faltas de pago en verano en los últimos 12 meses
% de faltas de pago en otoño en los últimos 12 meses
% de faltas de pago en invierno en los últimos 12 meses
Estas 4 características analizan los 12 meses anteriores y extraen el porcentaje de fallas dentro de cada temporada. Podemos personalizar más funciones según países específicos. Como actualmente estamos haciendo el análisis en los Emiratos Árabes Unidos, hemos agregado características culturales como:
% de faltas de pago en Ramadán
% de faltas en Eid
Entonces, llegamos al siguiente modelo de datos (muestra de las características):

Resultados
Después de construir nuestro modelo de aprendizaje automático y ejecutarlo en las características actuales, obtenemos el siguiente resultado:
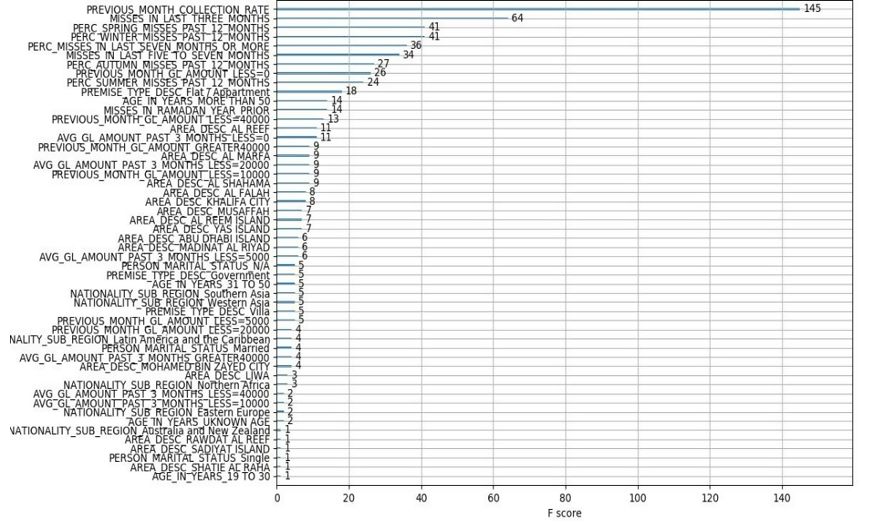
Y como se predijo, la característica más fuerte que tenemos es la que derivamos de la definición de caso de uso, que es:
Tasa de cobro del mes anterior: esta función es la tasa de cobro a partir del mes anterior.
Esto es seguido por nuestras características de ingeniería manual, tales como:
Faltas en los últimos 3 meses
Porcentaje de fallas en las diferentes estaciones
Faltas de pago en Ramadán/Eid
La forma en que calculamos la importancia relativa de las características es utilizando la puntuación F1:

Este es sólo el paso inicial. Cuando trabajamos en un proyecto de ciencia de datos, siempre hay un proceso continuo de mejora y prueba, a través de múltiples iteraciones.
Al evaluar sus características, recuerde que algunas características pueden parecer débiles o irrelevantes ahora, pero con algunas modificaciones y / o cambios en el contexto en el que se interpretan, pueden resultar características sólidas que podría ser útiles reincorporar más tarde.
El punto más importante es mantener siempre una mente abierta y tratar de pensar desde varias perspectivas con respecto a la ingeniería de características: a veces la respuesta menos obvia es la clave.