
Machine Learning e Inteligencia Artificial se usan a menudo como intercambiables (sinónimos), pero no lo son. Veamos primero cómo se relacionan entre sí.
¿Qué es la Inteligencia Artificial?
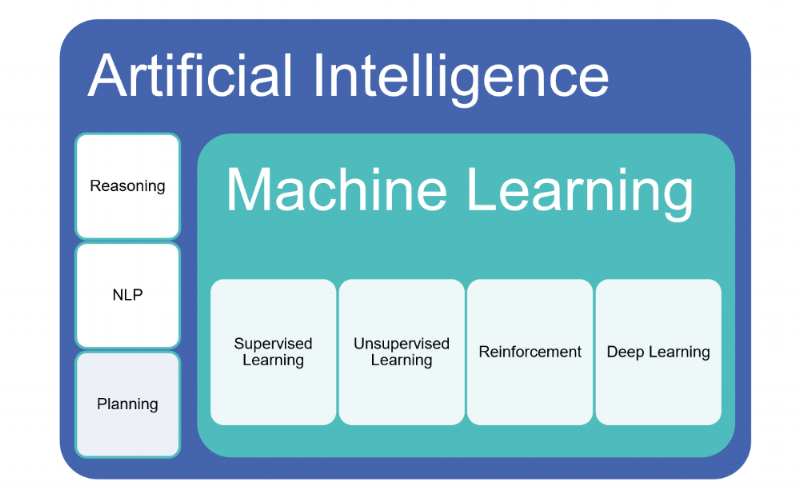
I.A. es la ciencia de entrenar a máquinas para realizar tareas humanas. I.A. sostiene el concepto de que una computadora puede actuar como un cerebro humano, calculando los pasos en el camino que nos rodea cada segundo de cada día. La Inteligencia Artificial incluye razonamiento, procesamiento cognitivo, reconocimiento del lenguaje natural, planificación y otros campos de investigación, además de Machine Learning

¿Qué es Machine Learning?
Machine Learning es un subconjunto específico de inteligencia artificial que entrena a las máquinas para aprender.
El nombre Machine Learning fue introducido por Arthur Samuel en 1959. Es un campo de la ciencia que explora el desarrollo de algoritmos que pueden aprender y hacer predicciones sobre los datos. La principal diferencia con otros algoritmos comunes es la pieza de "aprendizaje". Los algoritmos de Machine Learning no son series de procesos ejecutados en serie para producir un resultado predefinido. En su lugar, son una serie de procesos que buscan "aprender" patrones de eventos pasados y construir funciones que pueden producir buenas predicciones, con un grado de confianza.
Dentro del campo del análisis de datos, Machine Learning forma parte de una área conocida como análisis predictivo .
Los modelos de Machine Learning buscan patrones en los datos para tratar de esbozar conclusiones como lo harían las personas. Cuando el algoritmo es lo suficientemente bueno como para esbozzar las conclusiones correctas, aplica este conocimiento a nuevos conjuntos de datos.
Ciclo de aplicación de Machine Learning:

¿Qué necesita para funcionar bien?
Datos granulares
Grandes volúmenes de datos
Datos extremadamente diversos
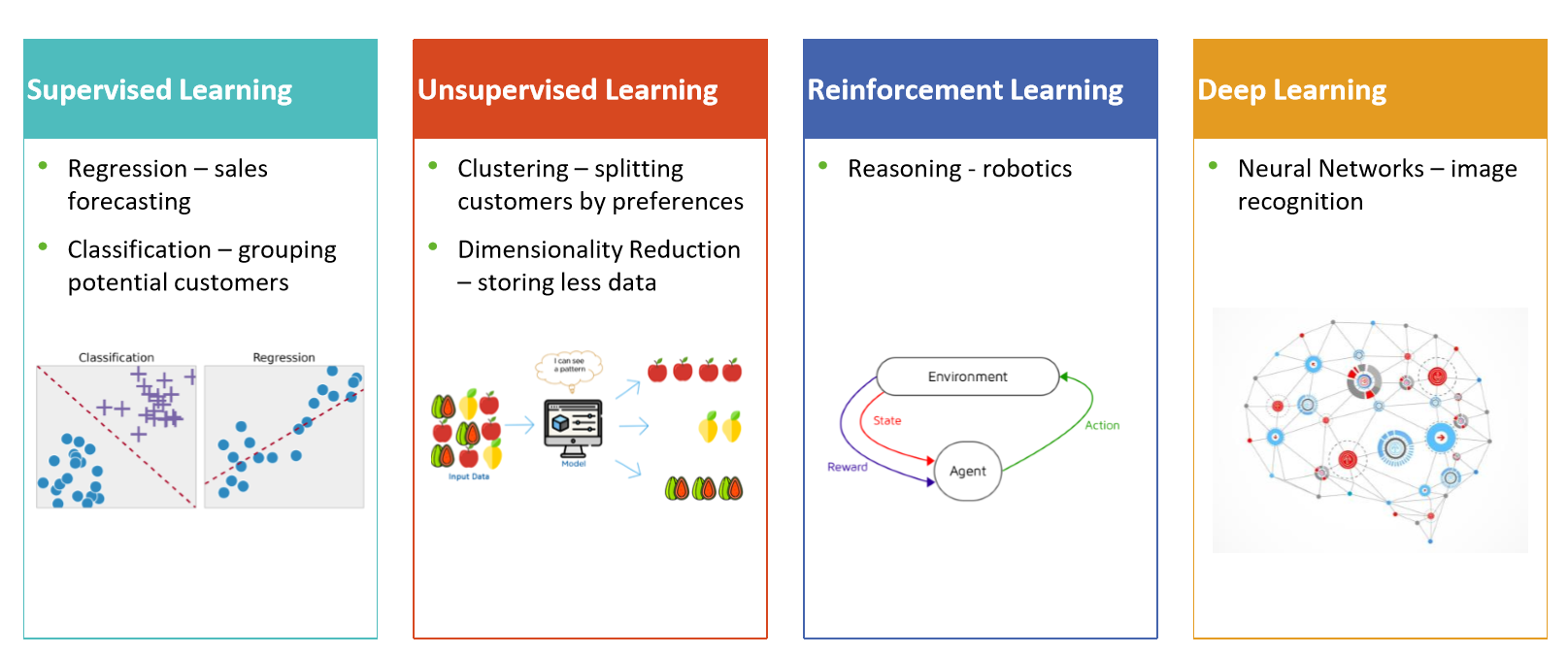
Los cuatro tipos de Machine Learning
MACHINE LEARNING SUPERVISADO
Está compuesto por algoritmos que intentan encontrar relaciones y dependencias entre un producto objetivo que queremos predecir, que va desde la rotación hasta el fraude de seguros o el éxito potencial de una promoción de ventas en diferentes individuos, y datos que tenemos de otros individuos del pasado, incluidas características demográficas o datos de comportamiento previos. Utilizamos estos datos pasados como variables de entrada para predecir el valor de salida más probable para los nuevos datos, en función de las relaciones aprendidas de los conjuntos de datos anteriores.

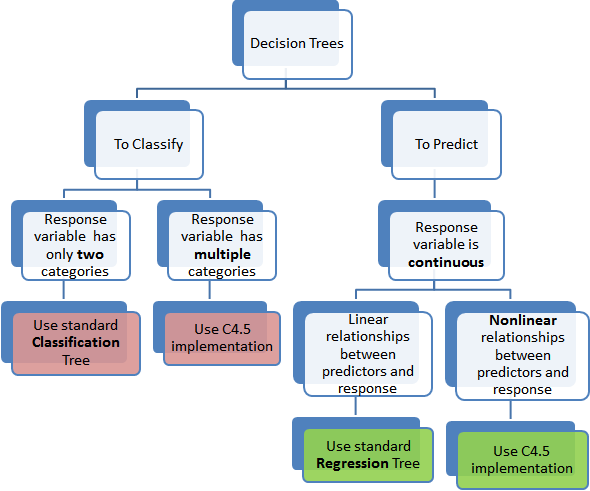
Árboles de Decisión
Los árboles de clasificación y regresión se conocen comúnmente como CART. El término fue introducido por Leo Breiman para referirse a los algoritmos de Árbol de Decisión que se pueden usar para problemas de modelado predictivo de clasificación o regresión.
El algoritmo básico de CART es la base para algoritmos más avanzados como árboles de decisión empaquetados, Random forest y árboles de decisión potenciados.
Los árboles de decisión generalmente se usan para predecir la probabilidad de lograr un resultado para una nueva observación (individuo, cliente, ...) según sus atributos (edad, demografía, comportamiento de compra, ...), utilizando datos anteriores que tenemos de un número suficiente de Observaciones similares o individuos. El resultado para predecir es normalmente binario: sí / no (se agitará / no se agitará, se comprará / no se comprará, ...).
Se denominan árboles porque se pueden representar como un árbol binario donde cada nodo raíz representa una única variable de entrada (edad, ciudad, segmento ...) y un punto de división en esa variable (suponiendo que la variable es numérica).
Los nodos de hoja del árbol contienen la variable de salida (comprará, batirá, ...) que queremos predecir. Comencemos con un ejemplo simple, donde trataremos de predecir el género en función de la altura y el peso de las personas. A continuación se muestra un ejemplo muy simple de un árbol de decisión binario:
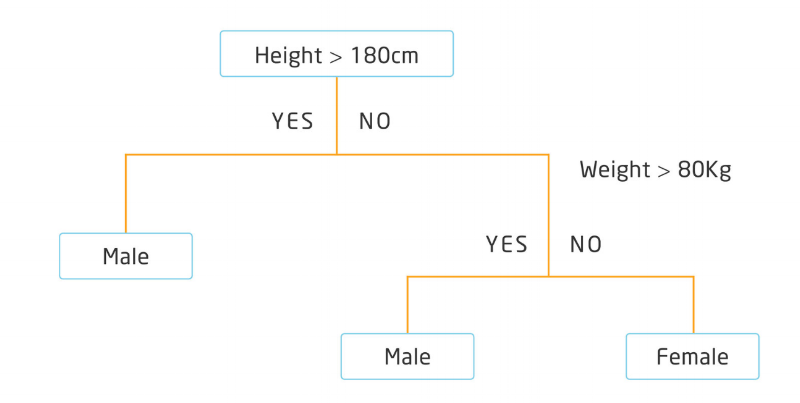
El árbol se puede representar tanto como un gráfico o como un conjunto de reglas. Por ejemplo, a continuación se muestra el árbol de decisiones anterior, que describe un conjunto de reglas:
Si Altura > 180 cm Entonces Hombres
Si Altura <= 180 cm y peso 80 kg Entonces Hombre
Si Altura <= 180 cm Y Peso <= 80 kg Entonces Mujer
Con la representación de árbol binario del modelo CART descrito anteriormente, hacer predicciones es relativamente sencillo. Cada vez que evaluamos a un nuevo individuo, podemos predecir su género según la altura y el peso, con un grado de confianza.
Los árboles de decisión son un método fácil de representar frecuencias de atributos que sospechamos que pueden proporcionar información, ayudando a predecir un resultado. Pueden ser muy útiles para analizar las causas probables de los buenos y malos resultados comerciales y ayudarnos a mejorar nuestros niveles de servicio, aumentar la retención de clientes o prevenir el fraude, entre muchas otras aplicaciones.
Regresión

Ex: Precios de Vivienda Regresión Lineal
Uso de datos etiquetados para hacer predicciones en forma continua .
La salida de la entrada siempre está en curso, y el gráfico es lineal .
La regresión es una forma de técnica de modelado predictivo que investiga la relación entre una variable dependiente [Outputs] y una variable independiente [Inputs].
Esta técnica utilizada para pronosticar el clima, el modelado de series de tiempo, la optimización de procesos.
Linear Regression – relationship between two variables by fitting a linear equation to the observed data.
Ex: Predicción del precio de la vivienda, donde el precio de la vivienda se predecirá a partir de las entradas, como el número de habitaciones, la localidad, la facilidad de transporte, la edad de la vivienda, el área de la vivienda.
Cómo un aumento en el impuesto (para el alcohol) tiene una influencia para una cantidad de cigarrillos empacados consumidos por día.
Cómo las horas de sueño afectan nuestras calificaciones en los cursos.
Ver correlación de experiencia por salarios.
La correlación entre el piso de la casa es versus el precio de la casa.
La segunda aplicación es pronosticar nuevas observaciones (valores no observados).
Clasificación
Es el tipo de aprendizaje supervisado en el que los datos etiquetados se utilizan para hacer predicciones en una forma no continua .
La salida de la información no siempre es continua, y el gráfico no es lineal .
En la técnica de clasificación, el algoritmo aprende de la entrada de datos que se le da y luego utiliza este aprendizaje para clasificar observaciones nuevas.
Este conjunto de datos puede ser meramente bi-class, o también puede ser multi-class.
Ex: Uno de los ejemplos de problemas de clasificación es verificar si el correo electrónico es spam o no spam entrenando el algoritmo para diferentes palabras spam o correos electrónicos. (Vecinos más cercanos a K, SVM, Kernel, Naïve Bayes, Árbol de Decisiones, Bosque Aleatorio)
Los árboles de clasificación se utilizan para separar el conjunto de datos en clases que pertenecen a la variable de respuesta. Generalmente, la variable de respuesta tiene dos clases: Sí o No (1 o 0).
Árboles de regresión son necesarios cuando la variable de respuesta es numérica o continua. Por ejemplo, el precio previsto de un bien de consumo. Por lo tanto, los árboles de regresión son aplicables para el tipo de predicción de problemas en oposición a la clasificación.
Ejemplos
Si desea predecir si una persona hará clic en un anuncio online

En comparación, el algoritmo de Random forest selecciona al azar observaciones y características para construir varios árboles de decisión y luego promedia los resultados.
En el dominio de la atención médica se utiliza para identificar la combinación correcta de componentes en la medicina y para analizar el historial médico de un paciente para identificar enfermedades. En el comercio electrónico, el bosque aleatorio se utiliza para determinar si a un cliente realmente le gustará el producto o no.
Entendiendo por qué los clientes se van
"Cuesta mucho menos mantener un cliente existente que ganar un nuevo cliente"
El proveedor de servicios móviles debe poder observar los patrones a partir de los datos y las anomalías. El proveedor de servicios móviles tiene la ventaja de tener acceso a grandes volúmenes de datos entre muchos clientes diferentes. Al utilizar el algoritmo correcto, el proveedor puede crear un modelo que mapee los tipos de ofertas y promociones que retendrán a los clientes y agregarán nuevos.
¿Cuánto costará retener y agregar nuevos clientes? ¿Los nuevos planes reducirán los ingresos significativamente? ¿El gasto justificará los esfuerzos? Estos son los tipos de predicciones que puede proporcionar una técnica de aprendizaje automático. ¿Cuál es la diferencia entre un enfoque de BI tradicional y un enfoque de aprendizaje automático para la rotación de clientes?

Evitar que ocurran accidentes
Industrias como fabricación, petróleo y gas, y servicios públicos tienen éxito o fracasan en función de su capacidad para evitar accidentes. Si bien es común tener un programa de mantenimiento, a menudo no es suficiente.
Por ejemplo, puede haber una falla en un sistema de calefacción o aire acondicionado. Podría haber un cambio dramático en las condiciones climáticas que podrían afectar la maquinaria.
Los algoritmos de aprendizaje automático pueden aplicarse al mantenimiento preventivo de varias maneras. Por ejemplo, un algoritmo de regresión se puede usar como base para un modelo que puede predecir el tiempo de falla de una máquina. Se pueden usar varios algoritmos de clasificación para modelar los patrones asociados con las fallas de la máquina. Los datos generados por los sensores proporcionan un gran volumen de datos semiestructurados que pueden modelar y comparar patrones de rendimiento para que se pueda detectar una anomalía en el rendimiento normal.
MACHINE LEARNING NO SUPERVISADO
Los datos sin etiquetar se utilizan para entrenar el algoritmo, lo que significa que se usó contra los datos que no tienen etiquetas históricas.
El propósito es explorar los datos y encontrar alguna estructura dentro.

Ex: puede identificar segmentos de clientes con atributos similares que luego pueden ser tratados de manera similar en campañas de marketing.
O puede encontrar los atributos principales que separan los segmentos de clientes entre sí.
Las técnicas populares incluyen mapas autoorganizables, mapas de redes cercanas, agrupación por k-medias y descomposición de valores singulares . Estos algoritmos también se utilizan para segmentar temas de texto, recomendar elementos e identificar valores atípicos de datos.
Agrupación
El análisis Clúster o agrupación en clúster es la tarea de agrupar un conjunto de objetos de tal manera que los objetos en el mismo grupo (denominado clúster ) sean más similares (en cierto sentido) entre sí que a los de otros grupos (agrupaciones).
La agrupación de clientes utiliza datos de transacciones de compra para rastrear el comportamiento de compra y luego crear nuevas iniciativas comerciales basadas en los hallazgos.
El objetivo de marketing típico es enfatizar y retener a los clientes de alto riesgo, alto valor y alto beneficio: este grupo "premium" que representa el 10-20 por ciento del total de compradores a menudo produce el 50-80 por ciento de las ganancias de una empresa.
Una vez que se identifica este grupo, debe considerar las técnicas de venta cruzada y venta cruzada que contribuirán aún más al potencial de rentabilidad de este grupo de datos atractivo.
Los árboles de decisión a veces se utilizan para campañas de marketing.
Es posible que desee predecir el resultado de enviar a los clientes y prospectos un cupón de 20 por ciento.
Puede dividir a los clientes en cuatro segmentos:
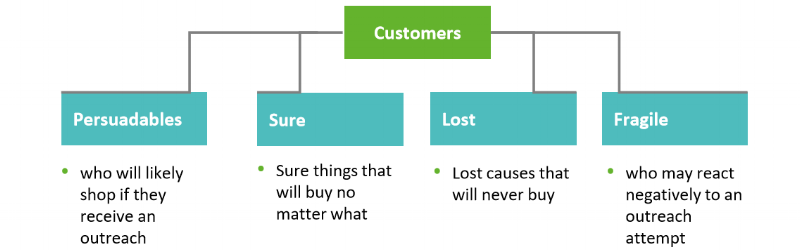
! Dirigirse a persuadables le dará el mejor retorno de la inversión (ROI). Un árbol de decisiones lo ayudará a identificar estos cuatro grupos de clientes y organizar prospectos y clientes según quién reaccionará mejor a la campaña de marketing.
Reducción de dimensionalidad
La reducción de la dimensión ayuda a los sistemas a eliminar datos que no son útiles para el análisis.
Este grupo de algoritmos se utiliza para eliminar datos redundantes, valores atípicos y otros datos no útiles.

La reducción de la dimensión puede ser útil cuando se analizan datos de sensores y otros casos de uso de Internet de las cosas (IoT). En los sistemas de IoT, puede haber miles de puntos de datos que simplemente le indican que un sensor está encendido. Almacenar y analizar los datos "en" no es útil y ocupará un espacio de almacenamiento importante. Además, al eliminar estos datos redundantes , el rendimiento de un sistema de aprendizaje automático mejorará.
Finalmente, la reducción de la dimensionalidad también ayudará a los analistas a visualizar los datos .
MACHINE LEARNING POR REFUERZO
El aprendizaje por refuerzo se utiliza a menudo para robótica, juegos y navegación.
Con el aprendizaje por refuerzo, el algoritmo descubre mediante prueba y error qué acciones producen las mayores recompensas.
Este tipo de aprendizaje tiene tres componentes principales: el agente (el aprendiz o el que toma las decisiones), el entorno (todo con lo que el agente interactúa) y las acciones (lo que el agente puede hacer).

Aprendizaje profundo | Redes Neuronales
El aprendizaje profundo - redes neuronales complejas - está diseñado para emular el funcionamiento del cerebro humano, de modo que las computadoras puedan recibir capacitación para lidiar con las abstracciones y los problemas que están mal definidos.
Las redes neuronales y el aprendizaje profundo a menudo se usan en aplicaciones de reconocimiento de imagen, voz y visión de computadora.

Detección de Rostro

Reconocimiento de Voz

Resumen
Casos de ejemplo de uso de Machine Learning
Industria manufacturera
Detección de anomalías en plantas de fabricación de acero: supervisar el proceso de producción
Chequeo de calidad en la industria del automóvil: monitorear el proceso de montaje
Gestión de inventario: estimar la condición del inventario.
retail
Recomprometer a los clientes rezagados: predice qué cliente es poco probable que regrese
Aumenta el tamaño promedio de los pedidos: haz recomendaciones más inteligentes
Reduzca el desperdicio de marketing: para conocer qué productos reciben la mejor respuesta del consumidor y adaptar las tácticas de mercadeo.
Marketing y Ventas
Lifetime Value: predictions about most budding customers early and target sales effort toward them
Churn: predicciones de quién se está yendo, reenfocando y personalizando el trato
Análisis de opiniones: análisis de NLP en los comentarios de los clientes
Seguridad
Filtrado de Spam
Detección de Fraude: bloqueo de clientes / transacciones de dinero potencialmente fraudulentas


